
Hallo allemaal, Leo hier. Today we will discuss how to remove data clump in Swift to decrease developer cognitive load.
Today we will talk about a code smell. Code smells are symptoms that something is not “well thought”, implying that it could/should be improved. Mind that the mere existence of a code smell is not the sole indicator of good or bad code. As I said, is a symptom and should be treated like that.
There are a plethora of code smells and also various ways to classify them. The code smell we will talk about today is Data Clump and how it can be bad for you (and other developers) if not wisely used.
Let’s code! But first…
Painting of The Day
The painting is a 19th-century art piece called A Crab on the Seashore by the master Utagawa Kunisada. Utagawa Kunisada lived from 1786 to 1865 and was the most popular, prolific, and commercially successful designer of ukiyo-e woodblock prints in 19th-century Japan. In his own time, his reputation far exceeded that of his contemporaries, Hokusai, Hiroshige, and Kuniyoshi.
At the end of the Edo period (1603–1867), Hiroshige, Kuniyoshi, and Kunisada were the three best representatives of the Japanese color woodcut in Edo (capital city of Japan, now Tokyo). However, among European and American collectors of Japanese prints, beginning in the late 19th and early 20th centuries, all three of these artists were regarded as rather inferior to the greats of classical ukiyo-e, and therefore as having contributed considerably to the downfall of their art. For this reason, some referred to their works as “decadent”.
I chose that piece because of the crab clamps! Be careful with them…
The problem – Remove Data Clump in Swift
You have objects, that are tightly together in various layers of your app.
The code smell we will study today is called Data Clump. And is a name given to any group of variables that are passed around together (in a clump) throughout various parts of the program.
As I said earlier, we have some ways to classify code smells in object-oriented programming.
Code Smells Classification
One way to classify is from a software structure perspective:
- Application-Level: smells that act on how your various parts of the application interact with each other.
- Class-Level: smells that act on how the class deals with its features.
- Method-Level: how a method deal with its complexity.
We could also classify by behavior:
- Bloaters – Pieces of code that tend to only increase and get big and unmaintainable.
- Object-Orientation Abusers – When you implement Object Orientation principles in the wrong way.
- Hard To Change – Smells that make your life difficult when trying to change something in the code.
- Dispensable – Parts of the code that can be simply deleted or refactored into much smaller code.
- Couplers – Code snippets that increase too much coupling and make things hard to change in the future.
A data clump, like other code smells, can indicate deeper problems with the program design or implementation and is an Application-Level and Bloater. The group of variables that typically make up a data clump are often closely related or interdependent and are often used together in a group as a result.
Code Smell Swift Example
Imagine that you have a login workflow. In that workflow, you create a view model and you need to get six pieces of information about the user: username, location, two-factor authentication boolean, password, timestamp, and one UUID of the device.
Something like this:
protocol LoginService { func makeLogin(username:String, location: String, fa2: Bool, password: Data, timestamp: Double, deviceUUID: String) }
struct LoginViewModel {
let loginService: LoginService
func makeLogin(username:String,
location: String,
fa2: Bool ,
password: Data,
timestamp: Double,
deviceUUID: String) {
// rest of the login logic
loginService.makeLogin(username: username,
location: location,
fa2: fa2 ,
password: password,
timestamp: timestamp,
deviceUUID: deviceUUID)
}
}It’s a very big function signature, and if stopped there wouldn’t be a big hassle. The problem is that we need to communicate all this data to other layers. Now everything that needs the login information will have that long signature.
If you are using protocols, and you should be using, you could end up with an architecture that looks like this:
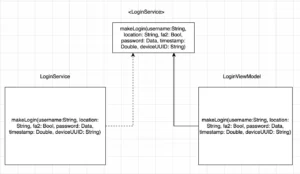
Now you can visualize how painful would be to just add or change one of the parameters. If you add a new parameter that would be used down the way in the layers, you need to change 3 files at least just to pass the new information. If you have unit tests, and you should, this could potentially be 5 or more files changed to just put one more attribute in a protocol.
The solution to Remove Data Clump in Swift
The most common solution ( but not the only one ) is to create an object that represents the clumped data. Well, if all the data is used together and we need to send it through various layers and functions, makes sense to transform that huge signature into an object.
In our case, the proposed solution is to create an object that holds all the data. Let’s examine the solution:
struct LoginData {
let username:String
let location: String
let fa2: Bool
let password: Data
let timestamp: Double
let deviceUUID: String
}
protocol LoginService {
func makeLogin(with loginData: LoginData)
}
struct LoginViewModel {
let loginService: LoginService
func makeLogin(with loginData: LoginData) {
// rest of the login logic
loginService.makeLogin(with: loginData)
}
}Now it’s much easier to maintain our codebase. If we eventually need to add or remove any property from the LoginData, we could simply change the struct and the code related to that specific property.
This solves our problems with the hard maintenance cost of that login flow and high cognitive load reading that giant function signature. But also brings side effects to our app architecture.
The Architecture Ripple Effect
Let’s revisit the previous architecture and compare it with the new one.
Old Architecture:
New Architecture:
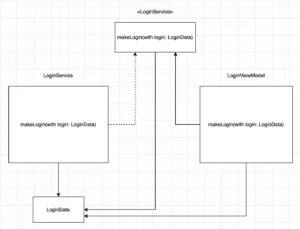
Now you can see what side effects we bring to our structure. Every time we create an object to solve a Data Clump problem we increase the number of dependencies of everyone involved.
Yes, it’s the maintenance is easier but now you need to make a decision, on where the LoginData will live? I think everyone reading this will say: “In the model layer”.
But if the LoginData lives in the model layer it implies that the view should know the model layer and that is also something to take into account. One good architecture principle is: Changes in the inner layers should affect only the outer layer, not the outer-outer layer. Deciding put this new object into the model layer, when you have to change it will necessarily change the view-model and the view layer.
Continue Studying
Today we discussed a lot about removing cognitive bias, but there are others ways to do that. When you organize a good delegation everyone including you using that code base is happy to read and see the code organized.
You can use abstractions to make your code more expressive using less repetitive structures, that is when comes handy the factory pattern. That abstracts everything that an object needs to configure for you.
Wrap up
To solve our new coupling problem each layer should need its version of LoginData so we could decouple all the layers between them. But again, this brings the side effect of code repetition and mapper functions between all layers. Do you realize that there is no perfect solution?
It’s important to have an educated decision about what your APIs will look like. And the advantages and drawbacks of each one. It’s always a matter of deciding what is best for your case.
Summary – Remove Data Clump to Decrease Developer Cognitive Load in Swift
There’s no right or wrong in any of those decisions. If you want to keep the Data Clump because you don’t want to create more complex structures it’s your decision. In the same way, if you decide to create new structures to solve the Data Clump and create more complexity between layers.
That’s all my people, I hope you liked reading this article as much as I enjoyed writing it. If you want to support this blog you can Buy Me a Coffee or leave a comment saying hello. You can also sponsor posts and I’m open to freelance writing! You can reach me on LinkedIn or Twitter and send me an e-mail through the contact page.
Thanks for reading and… That’s all folks.
Credits:



